Speed up Python code with CARMA
Python is lovely, but what if you want something both lovely and fast?
I’ll show you how to get a factor 250x speedup using wrapped C++ code.

It’s not Python’s fault — more that of all interpereted languages. We start out by writing an algorithm that we understand, but is terrible in performance. We can try to optimize the code by reworking the algorithm, adding GPU support, etc., etc., but let’s face it: optimizing code by hand is exhausting. Don’t you just wish there were a magic… thing… existed that you could run over your code to make it faster? A magic thing called a… compiler?
pybind11 is a fantastic library you can use to wrap C++ code into Python — and the modern C++ compiler is a magic optimization wizard.
- For a tutorial to get started with
Python,C++andpybind11usingCMake, see this article here. - For a tutorial on some advanced features in
pybind11, see this article here.
The most common package in Python has to be NumPy — NumPy arrays are absolutely everywhere. In C++, the Armadillo library is highly optimized, easy to use, and widely adopted (did you know MLPack is built on Armadillo?). The common Armadillo data types are for matrices and column and row vectors. Chances are: if you have an algorithm in Python using NumPy, you will be easily able to rewrite it with the methods native to Armadillo.
CARMA is exactly what you wanted — a library to help you wrap back and forth between Armadillo and NumPy data types. It’s exactly what a C++ library should be — header only, well documented, and powerful. You can grab the source for CARMA here, and the documentation here.
Here we will use CARMA to wrap a simple Gibbs sampler for an Ising model.
You can find the entire code for this project here.
Overview of CARMA
Let’s check out the main commands in CARMA:
There are also similarly commands for row vectors and cubes.
For efficiency, it’s crucial to think about when an object is copied or not. The default behavior is a little confusing:
- Everything is not copied by default, except:
- Armadillo column/row vectors to NumPy arrays are copied by default.
To change the default behavior, check out convertors.h in the CARMA source. You can instead use the signatures:
Gibbs Sampler algorithm
Let’s review a super simple Gibbs sampler algorithm. First, initialize a 2D lattice of -1/+1 spins. Then, iteratively:
- Choose a random lattice site.
- Calculate the difference in energy if we flip the spin:
Energy diff = Energy after — energy before. - Accept the flip with probability
exp(Energy diff), i.e. generate a random uniformrin[0,1]and accept the flip ifr < min(exp(Energy diff), 1).
For the 2D Ising model with coupling parameter J and bias b, the energy difference for flipping spin s with neighbors s_left, s_right, s_down, s_up:
- 2 * b * s — 2 * J * s * ( s\_left + s\_right + s\_down + s\_up )
Pure Python ===============

Let’s start with a simple pure **Python** implementation of the Gibbs Sampler. Make a file simple_gibbs_python.py with contents:
We have two methods: one with returns a random state (a 2D NumPy array of 0 or 1), and one which takes an initial state, samples it, and returns the final state.
Let’s write a simple test for it. Make a file called test.py with contents:
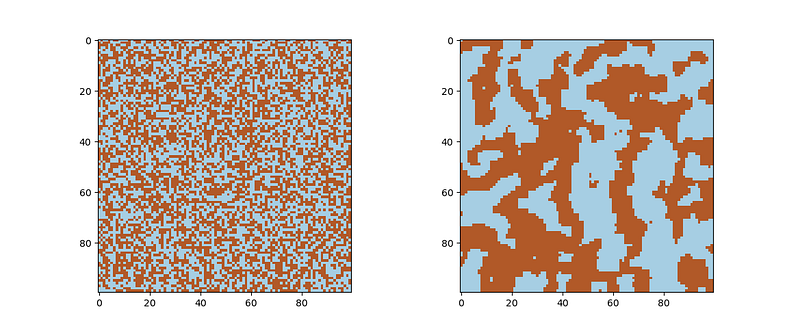
Here we create a 100x100 lattice with bias 0 and coupling parameter 1. We sample for 100,000 steps. Below are a examples of an initial state and a final state:
Timing the code gives:
Duration: 2.611175 seconds
That’s way too long! Let’s try to write the same code in C++ and see if we get an improvement.
Pure C++

Next, let’s write a simple library in C++ to do the same thing. We will organize the directory as follows:
gibbs\_sampler\_library/cpp/CMakeLists.txt
gibbs\_sampler\_library/cpp/include/simple\_gibbs
gibbs\_sampler\_library/cpp/include/simple\_gibbs\_bits/gibbs\_sampler.hpp
gibbs\_sampler\_library/cpp/src/gibbs\_sampler.cpp
The reason for placing the entire project in the cpp folder inside another folder called gibbs_sampler_library will be to enable us to wrap it into Python later.
The CMake file is used to build a library called simple_gibbs:
The header file is:
and the source file is:
Notice again that we didn’t rewrite the code in any smarter way — we have the same for loops and approach as in Python.
We can build the library with
cd gibbs\_sampler\_library/cpp
mkdir build
cd build
cmake ..
make
make install
There is also a simple helper header file include/simple_gibbs:
#ifndef SIMPLE\_GIBBS\_H
#define SIMPLE\_GIBBS\_H
#include “simple\_gibbs\_bits/gibbs\_sampler.hpp”
#endif
such that we can simply use #include <simple_gibbs> later.
Next, let us make a simple test test.cpp for our library:
We can again build this using a CMake file, or just:
g++ test.cpp -o test.o -lsimple\_gibbs
Running it gives (on average):
Duration: 50 milliseconds
Wow! That’s 500x faster than the Python code! Notice again that we didn’t rewrite the code in C++ in the gibbs_sampler.cpp file in any smarter way — we have the same for loops and approach as in Python. It’s the magic of optimization in modern C++ compilers that gave us that great improvement.
That is true luxury of compiled languages that even other optimization approaches in Python cannot rival. For example, we could have used cupy (Cuda + NumPy) to take advantage of GPU support, and rewritten the algorithm to use more vector and matrix operations. Certainly this will boost performance, but it is hand-tuned optimization. In C++, the compiler can help us optimize our code, even if we remain ignorant of it’s magic.
But now we want to bring our great C++ code back into Python — enter CARMA.
Wrapping the C++ library into Python using CARMA

CARMA is a great header-only library for converting between Armadillo matrices/vectors and NumPy arrays. Let’s jump right in. The directory structure is:
gibbs\_sampler\_library/CMakeLists.txt
gibbs\_sampler\_library/python/gibbs\_sampler.cpp
gibbs\_sampler\_library/python/simple\_gibbs.cpp
gibbs\_sampler\_library/python/carma/…
gibbs\_sampler\_library/cpp/…
There are two folders here:
gibbs_sampler_library/cpp/…— this is all theC++code from the previous part.gibbs_sampler_library/python/carma/…— this is theCARMAheader-only library. Go ahead and navigate to the GitHub repo and copy theinclude/carmalibrary into thePythondirectory. You should have:
gibbs\_sampler\_library/python/carma/carma.h
gibbs\_sampler\_library/python/carma/carma/arraystore.h
gibbs\_sampler\_library/python/carma/carma/converters.h
gibbs\_sampler\_library/python/carma/carma/nparray.h
gibbs\_sampler\_library/python/carma/carma/utils.h
Now let’s look at the other files. The CMake file can be used to build the Python library:
Note that pybind11_add_module takes the place of the usual add_library, and has many of the same options. When we use CMake here, we have to specify:
cmake .. -DPYTHON\_LIBRARY\_DIR=”~/opt/anaconda3/lib/python3.7/site-packages” -DPYTHON\_EXECUTABLE=”~/opt/anaconda3/bin/python3"
Make sure you adjust your paths accordingly.
The main entry point for the Python library is the simple_gibbs.cpp file:
So far, CARMA hasn’t made an appearance. Let’s change that in the gibbs_sampler.cpp file.
There are two ways to convert between NumPy arrays and Armadillo matrices:
I’m going to cover the manual conversion, since it’s clearer. Automatic conversion will save you writing a couple lines, but it’s nice to see what can be done in general.
To use the manual conversion, we’re gonna make a new subclass of GibbsSampler called GibbsSampler_Cpp.
- It inherits the constructor from
GibbsSampler, since it doesn’t involve Armadillo. - The first method is:
Note this is the same name as the C++ method arma::imat get_random_state() const, but with a Python return signature. We called the pure C++ method, and converted the returned matrix back into NumPy. Also note that we have to import #include <pybind11/NumPy.h> to use py::array_t<double>.
- Similarly, the second method is:
Here we are converting both in the input from NumPy to Armadillo, and the output back from Armadillo to NumPy.
Finally, we must wrap the library using the standard pybind11 glue code:
Note that we renamed the classes from C++ to Python:
GibbsSamplerinC++->GibbsSampler_ParentinPython(exposed but methods not wrapped).GibbsSampler_CppinC++->GibbsSamplerinPython.
This way, we can use the same notation GibbsSampler in Python at the end.
The complete python/gibbs_sampler.cpp file is:
Go ahead and build that:
cd gibbs\_sampler\_library
mkdir build
cd build
cmake .. -DPYTHON\_LIBRARY\_DIR=”~/opt/anaconda3/lib/python3.7/site-packages” -DPYTHON\_EXECUTABLE=”~/opt/anaconda3/bin/python3"
make
make install
Make sure you adjust your paths.
Test the wrapped library in Python
Exciting! Hard work but we are ready to test our C++ library wrapped into Python. In the test.py file from the “Pure Python” section above, we can just change one import line as follows:
import simple\_gibbs\_python as gs
to
import simple\_gibbs as gs
and run it again. The output I get is:
Duration: 0.010237 seconds
Bang! That’s 250x faster, even with the conversions! The pure C++ code was 500x faster, so we get a factor 1/2 slowdown from the overhead of (1) calling the C++ code and (2) converting between NumPy arrays and Armadillo matrices. Still, the improvement is significant!
Final thoughts
That’s all for this intro. All credit to CARMA, not the least for it’s great documentation.
There are other optimizations available in Python — the point here is not to push the Python code (or the C++ code) to it’s limit, but to show how a vanilla C++ implementation can be used to speed up a vanilla Python code. Besides, in Python we focus on legibility — writing human readable algorithms. Using C++ to speed up Python is great because we can let the compiler do the work of optimizing instead of polluting our code, keeping our algorithm simple and clean.
You can find the entire code for this project here.
Related articles in Practical Coding:
- For a tutorial to get started with
Python,C++andpybind11usingCMake, see this article here. - For a tutorial on some advanced features in
pybind11, see this article here.
Contents
Oliver K. Ernst
July 12, 2020