From minimize to tf.GradientTape
A simple optimization example with Tensorflow 2.0.

I’ve often used tf.GradientTape from StackOverflow snippets, hastily glued together. I’ve also often used tf.GradientTape , and the minimize method usually appears. Finally I’ve separated the two in my mind in a simple application: optimizing a 1D function, e.g. (x-4)**2 in one scalar variable x.
The relationship between the two approaches is actually quite simple:
- One optimization method is to use the
minimizemethod, as documented here, which performs two steps:- It uses
tf.GradientTapeto calculate the gradient. - It uses
apply_gradientsto apply the gradients to the parameters.
- It uses
- The other method is to unpack the action of the
minimizemethod and manually perform these two steps.
Optimization using minimize
As a simple example, consider minimizing (x-4)**2 in one scalar variable x . To do so, we define a loss_function() , which must take no arguments.
loss_functionis the loss functionrunis the run function starting from an initial guess.- Iteratively, we apply the
opt.minimize(loss_function, var_list=[x])function to minimize the loss function with respect to the variable list. - We stop if the error tolerance is sufficiently low.
minimizeautomatically updates the iterations (actually:apply_gradientsis updating the iterations, which is called byminimize), and we stop if we hit the limit.
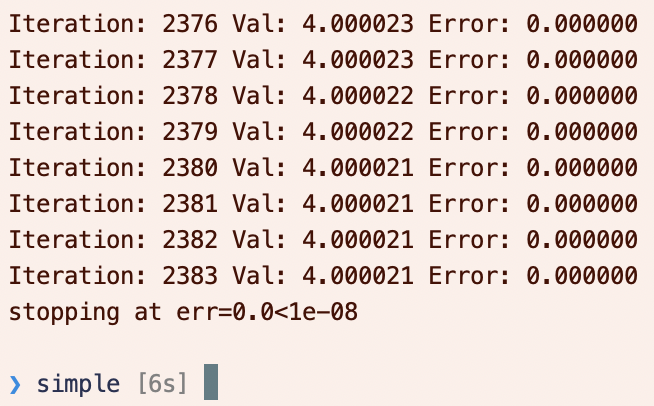
The output should be something like the following:
Optimization using tf.GradientTape
Alternatively, we can use the tf.GradientTape and apply_gradients methods explicitly in place of the minimize method.
- We no longer need a loss function.
- We use
with tf.GradientTape(persistent=False) as tto create the tape, and thent.gradient(y,[x])to calculate the gradient inywith respect tox. - Note: you may be surprised that we can exit the
withindentation and still access the tapet! In this case, you need to familiarize yourself with “blocks” as discussed here. The scope of variables extends throughout a block, which is either a module, function or a class. Since thewithstatement is not one of these, then you can still access the gradient tape! You may have previously seen thewithstatement used like this:
with open(fname,"r") as f:
...
But even here, even though the file is closed when the with statement ends, the variable f is not out of scope.
- We apply the gradients to
xwithopt.apply_gradients(zip(gradients,[x])).
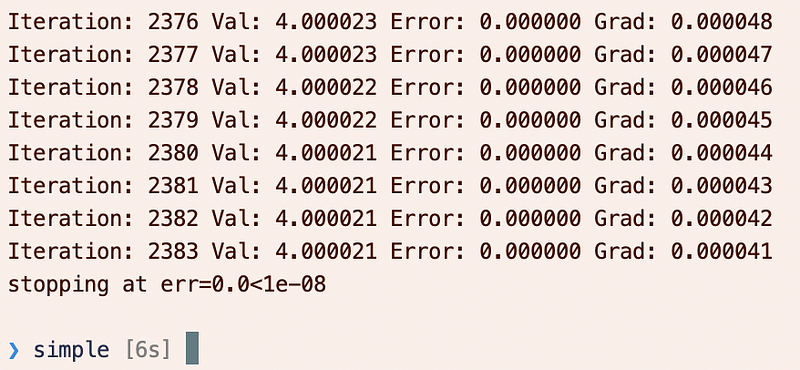
The output should be similar, but now we also have gradient information:
Final thoughts
Pretty simple, really!
A couple last notes on tf.GradientTape :
- Most times you do not need to call
t.watch(x)— from the documentation, “By default GradientTape will automatically watch any trainable variables that are accessed inside the context.” You can disable this in the constructor of thetf.GradientTape. - When do you need to use
persistent=True: you really only need this when you have defined an intermediate variable that you also want the gradient with respect to. For example, the following will **not** work:
with tf.GradientTape(persistent=False) as t:
z = x-4
y = z**2
grad\_z = t.gradient(z,x)
grad\_y = t.gradient(y,x)
Even though t is still in scope after the with block (see discussion above), from the documentation: “By default, the resources held by a GradientTape are released as soon as GradientTape.gradient() method is called.”. So the second gradient call will fail.
Instead, you should use:
with tf.GradientTape(persistent=True) as t:
z = x-4
y = z**2
grad\_z = t.gradient(z,x)
grad\_y = t.gradient(y,x)
# Don't forget now to do garbage collection when done computing gradients!
del t
Don’t forget the del t after you’ve computed all the gradients you’re interested in.
Contents
Oliver K. Ernst
September 29, 2020