Export Safari reading list using Python
Clean up your teeming reading list.

Here is the GitHub repo. with the script.
If you are like me, your reading list is overflowing. Mine is over 1000+ entries. I use it daily to quickly remind myself of useful websites I’ve found, but I never bother to clean it up after those sites have used their purpose.
I didn’t want to clean it up manually by clicking through 1000+ items with a mouse is tedious. There is a shortcut to remove all items, but before doing that I wanted to export the data.
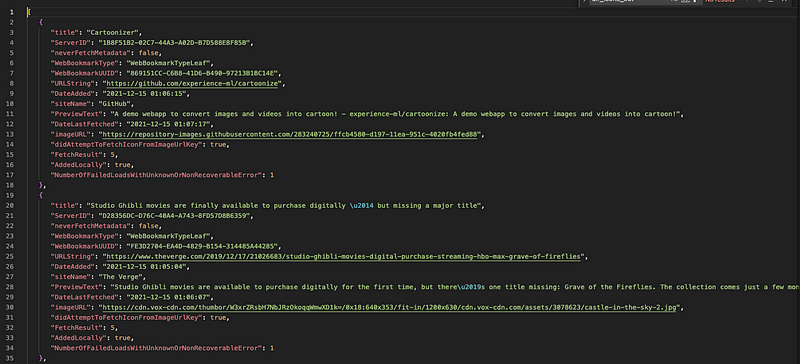

Here’s how it’s done.
Your reading list is stored in ~/Library/Safari/Bookmarks.plist (at least, in Mac 11.4 Big Sur it is). Additionally, icons for the reading list are stored in ~/Library/Safari/ReadingListArchives .
To read the .plist file format in Python, it is easiest to use the plistlib library:
pip install plistlib
The complete script
Here is the complete script — the explanation is below:
Usage
Basic usage:
- Export to CSV:
python export\_reading\_list.py csv reading\_list.csv
will write the reading list to reading_list.csv.
- Export to JSON:
python export\_reading\_list.py json reading\_list.json
will write the reading list to reading_list.json.
Options:
- Also copy the reading list icons:
python export\_reading\_list.py csv reading\_list.csv — dir-icons-out reading\_list\_icons
copies the icons to the folder reading_list_icons. They match up to the entries through the WebBookmarkUUID key.
- Specify the source directory for the icons:
python export\_reading\_list.py csv reading\_list.csv — dir-icons ~/Library/Safari/ReadingListArchives
The default is ~/Library/Safari/ReadingListArchives.
- Specify the source directory for the reading list
.plistfile:
python export\_reading\_list.py csv reading\_list.csv — fname-bookmarks ~/Library/Safari/Bookmarks.plist
The default is ~/Library/Safari/Bookmarks.plist.
- Include cached data for the websites:
python export\_reading\_list.py csv reading\_list.csv — include-data
The data is written to the Data field. The default is the--exclude-data option, which excludes the data.
Explanation of the script
First, copy the plist file for safety:
Next, find reading list elements in this terribly formatted dictionary:
Convert the reading list dictionaries to custom objects:
Finally, dump the entries to JSON or CSV:
Final thoughts
Now we have a backup of the reading list. A future project may write an edited CSV or JSON file back to the reading list plist format recognized by Safari.
Contents
Oliver K. Ernst
December 16, 2021